

本投稿ではOCRエンジンであるTesseract(テッセラクト)をインストールします。
画像の文字を認識し、テキストファイルに出力することができます。
Linux、Windows、MacとさまざまなOS上で動作することができますが
今回はMacにTesseractをインストールします。
前提としてHomebrewのインストールが必要です。
まだの方は以下投稿を参考に構築してみてください。

Google Colabolatoryでpyocrの検証をしている記事も投稿しています。
ご興味のある方はどうぞ!

環境情報
| Mac | Big Sur 11.2.3 |
| Homebrew | 3.0.10 |
| Tesseract | 4.1.1 |
Tesseractのインストール
brew install tesseract
Tesseractのインストールが終わりました。
最後の文章の通り、英語しか言語が入っていません。
This formula contains only the “eng”, “osd”, and “snum” language data files.
If you need any other supported languages, run `brew install tesseract-lang`.
上記の通り、他の言語もまとめてインストールしてしまいます。
brew install tesseract-lang
日本語が入っているか確認しましょう。
tesseract —list-langs | grep “jpn”
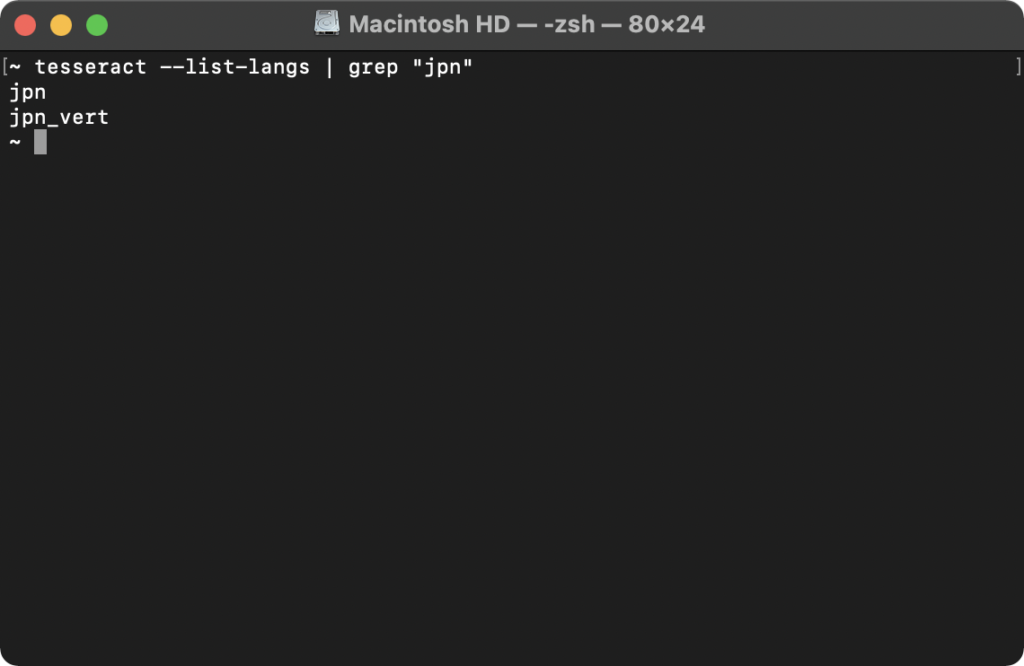
「jpn_vert」は縦書きの日本語です。(vert=verticalということで垂直ですね)
tesseractコマンドを上記のように使用できているのであれば正常にインストールできています。
Mac(M1)では以下のディレクトリにインストールされます。
/opt/homebrew/Cellar/tesseract/4.1.1
Tesseractをためしてみる
tesseractコマンドの構文は以下となります。
tesseract imagename outputbase [options…] [configfile…]
画像を用意してTesseractコマンドで画像を読み込んでみましょう。
tesseract test.png out
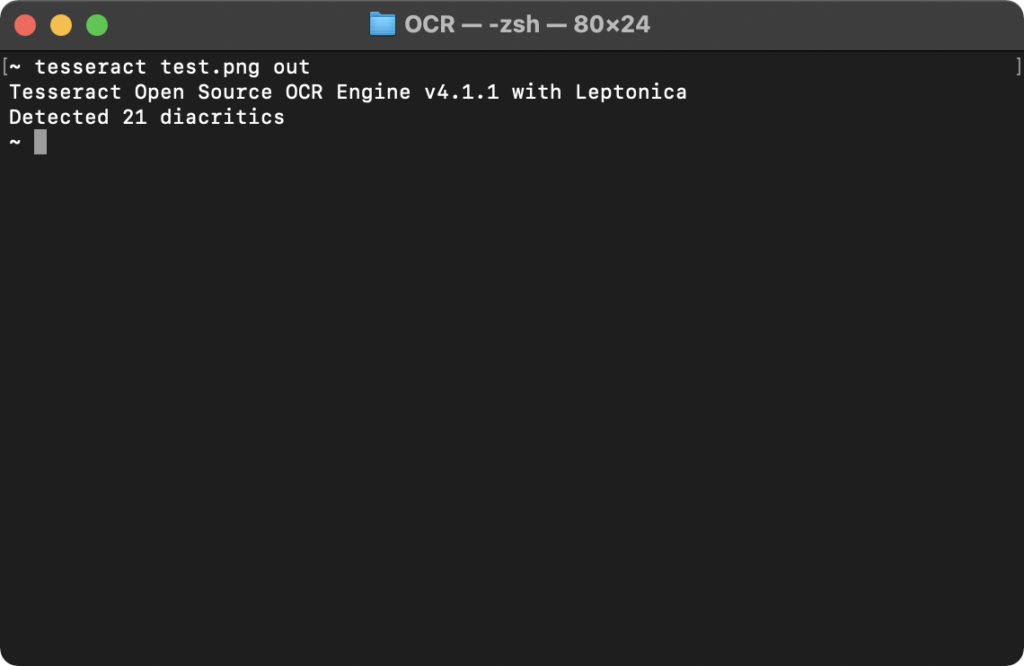
imagenameで画像ファイルを指定し、outputbaseに出力するテキストファイル名を入力します。
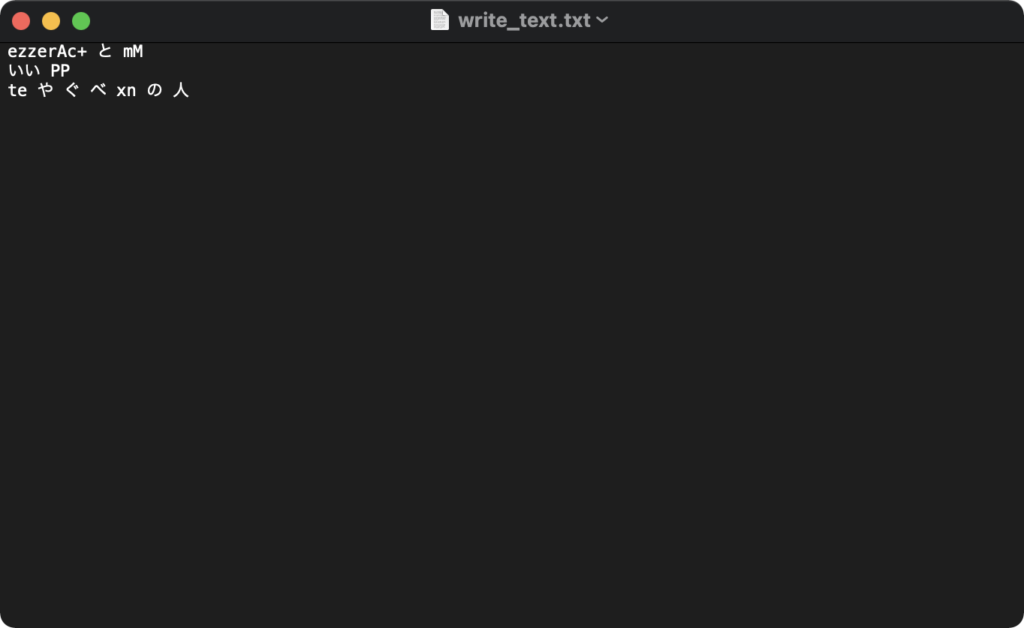
上記コマンドでは以下のように出力されました。
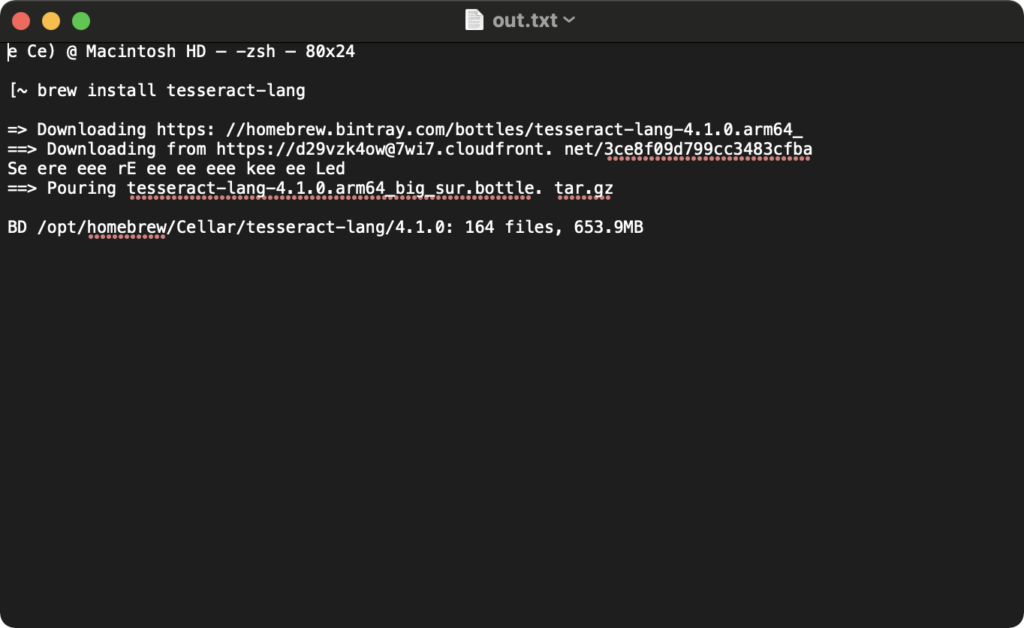
他言語をインストールした時のスクリーンショットを読み込ませた結果がout.txtに出力されました。
再度スクショを下に貼りますがしっかりと文字として認識できていますね。
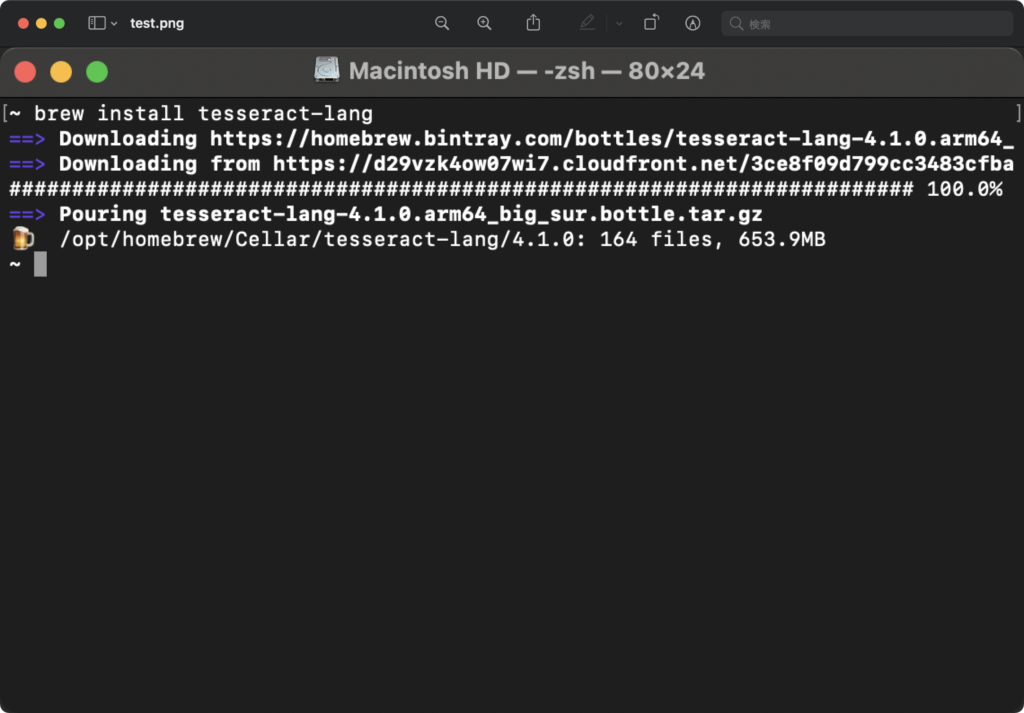
続いては日本語を読み込ませてみます。
読み込ませる画像は以下です。(iphoneのメモ帳をスクショ)
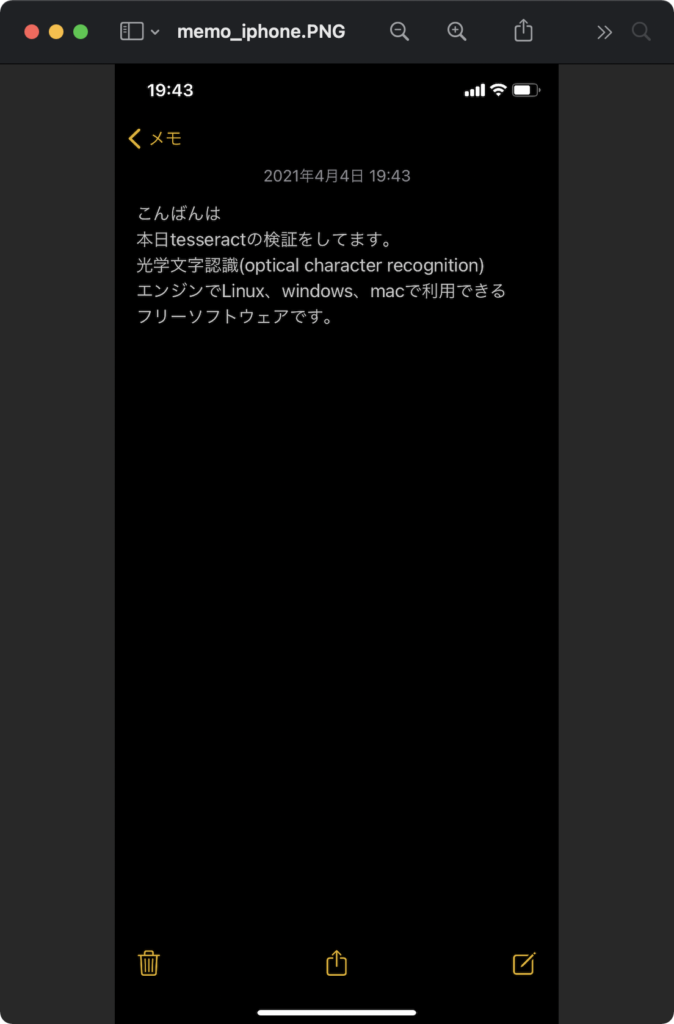
tesseractのオプションで日本語に対応できるようにしましょう。
tesseract memo_iphone.PNG memo_iphone -l jpn+eng
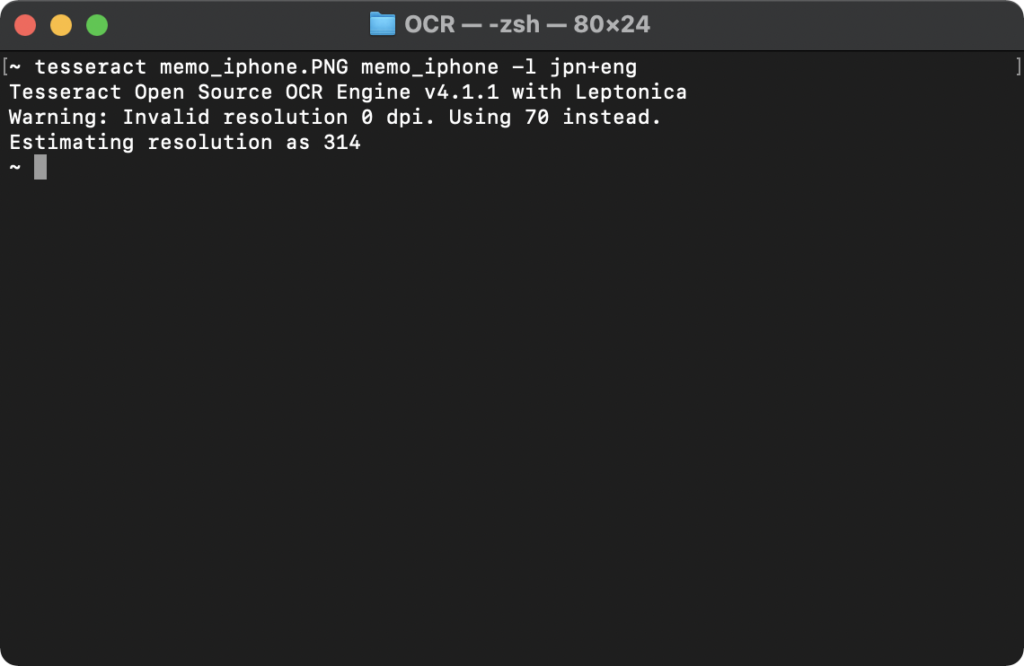
結果は以下です。
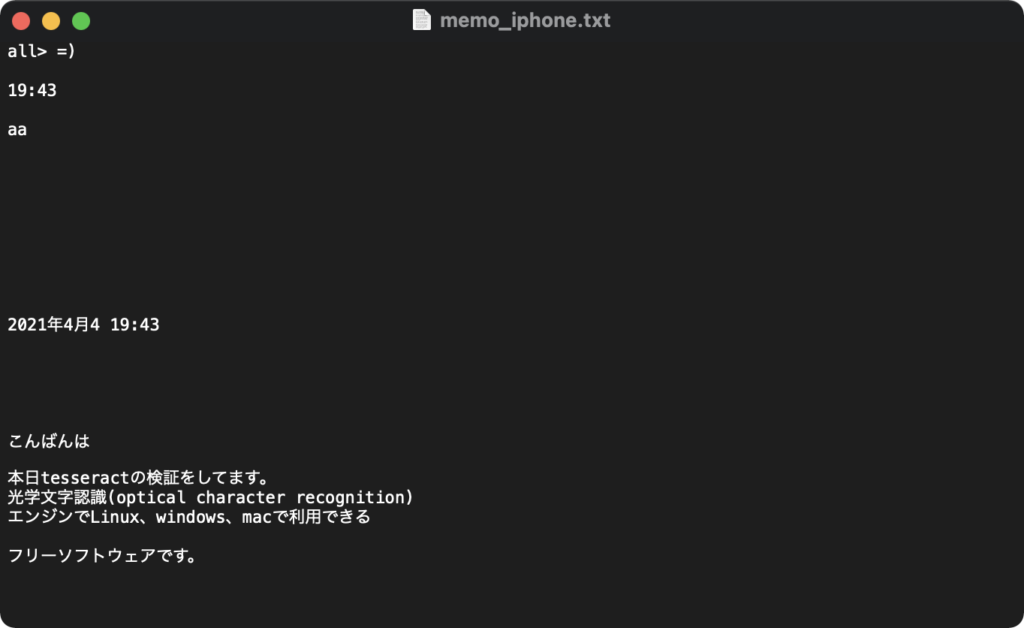
オプション「-l」で言語を選択します。複数の言語を使用する場合は「+」を使います。
今回は日本語、英語を指定しました。正しくスクショの内容をテキストとして出力できました。
最後に縦書きと横書きが入り混じった画像で検証してみます。
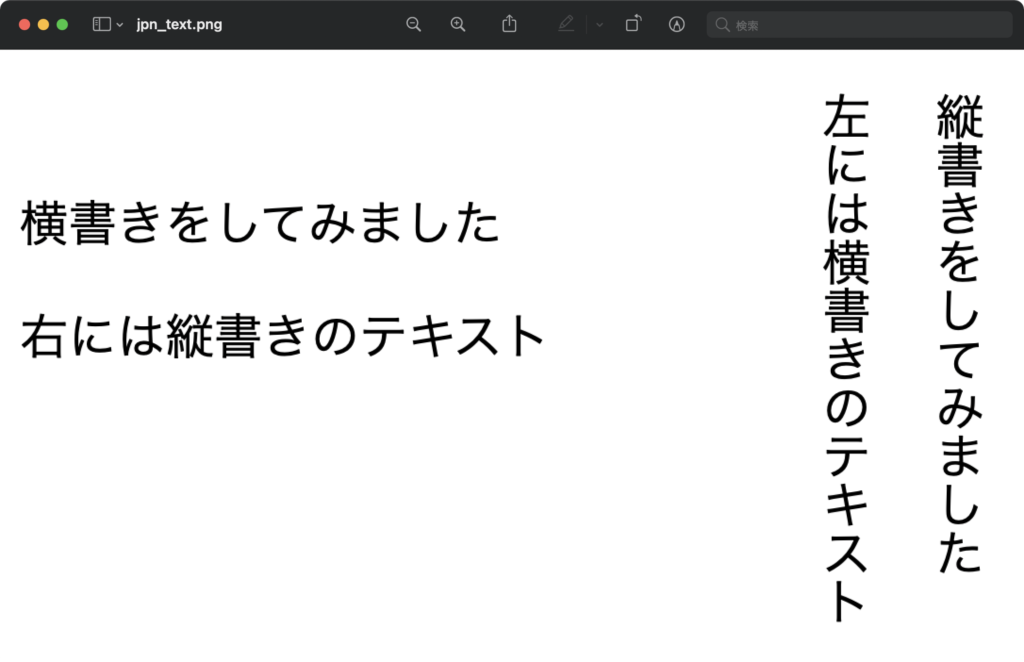
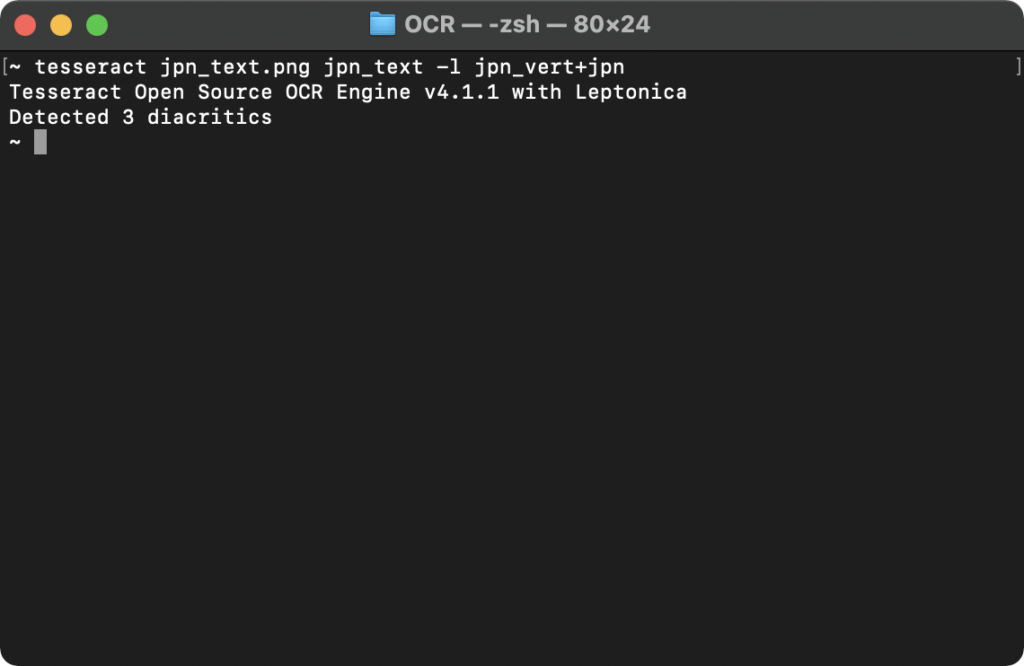
tesseract jpn_text.png jpn_text -l jpn_vert+jpn
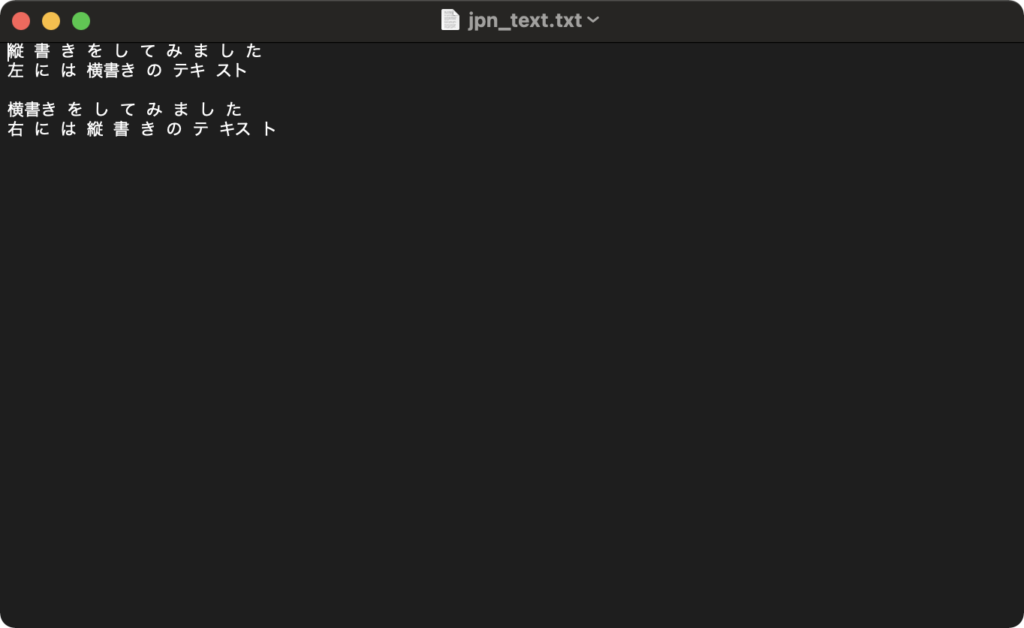
jpn_vertを指定することで縦書きの画像データもちゃんと認識してくれました。
日本語の手書きはうまくいきませんでしたので進展あれば投稿しようと思います。
手書きの画像

出力結果
(Tesseractの部分は少しだけ頑張ってくれた。)

コメント